The bit level data interchange format¶
Introduction¶
Bitproto is a fast, lightweight and easy-to-use bit level data interchange format for serializing data structures.
The protocol describing syntax looks like the great protocol buffers , but in bit level:
proto example
message Data {
uint3 the = 1
uint3 bit = 2
uint5 level = 3
uint4 data = 4
uint11 interchange = 6
uint6 format = 7
} // 32 bits => 4B
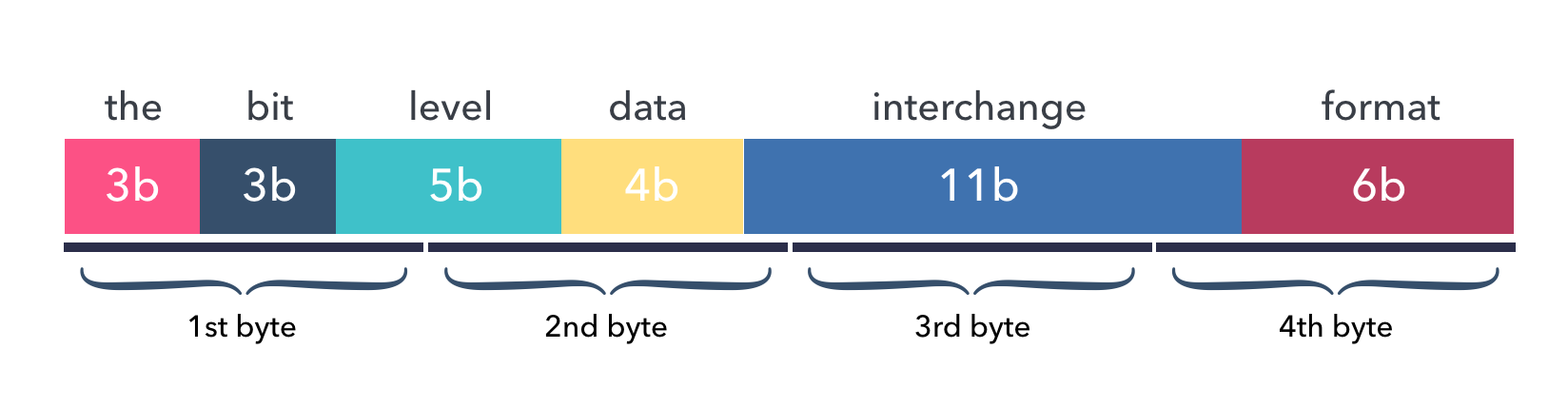
The Data above is called a message, it consists of 7 fields and will occupy a total
of 4 bytes after encoding.
This image shows the layout of data fields in the encoded bytes buffer:
Features¶
Supports bit level data serialization, born for embedded development.
Supports protocol extensiblity, for forward-compatibility.
Easy to start, syntax is similar to the well-known protobuf.
Supports languages: - C (without dynamic memory allocation), Go, - Python.
Blazing fast encoding/decoding, benchmark.
We can clearly know the size and arrangement of encoded data, fields are compact without a single bit gap.
Code Example¶
Code example to encode bitproto message in C:
struct Data data = {.the = 7,
.bit = 7,
.level = 31,
.data = 15,
.interchange = 2047,
.format = 63};
unsigned char s[BYTES_LENGTH_DATA] = {0};
EncodeData(&data, s);
// length of s is 4, and the hex format is
// 0xFF 0xFF 0xFF 0xFF
And the decoding example:
struct Data d = {0};
DecodeData(&d, s);
// values of d's fields is now:
// 7 7 31 15 2047 63
Simple and green, isn’t it?
Code patterns of bitproto encoding are exactly similar in C, Go and Python. Please checkout the quickstart document for further guide.
Why bitproto ?¶
There is protobuf, why bitproto?
Origin¶
The bitproto was originally made when I’m working with embedded programs on micro-controllers. Where usually exists many programming constraints:
tight communication size.
limited compiled code size.
better no dynamic memory allocation.
Protobuf does not live on embedded field natively, it doesn’t target ANSI C out of box.
Scenario¶
It’s recommended to use bitproto over protobuf when:
Working on or with microcontrollers.
Wants bit-level message fields.
Wants to know clearly how many bytes the encoded data will occupy.
For scenarios other than the above, I recommend to use protobuf over bitproto.
Vs Protobuf¶
The differences between bitproto and protobuf are:
bitproto supports bit level data serialization, like the bit fields in C.
bitproto doesn’t use any dynamic memory allocations. Few of protobuf C implementations support this, except nanopb.
bitproto doesn’t support varying sized data, all types are fixed sized.
bitproto won’t encode typing or size reflection information into the buffer. It only encodes the data itself, without any additional data, the encoded data is arranged like it’s arranged in the memory, with fixed size, without paddings, think setting aligned attribute to 1 on structs in C.
Forward-compatibility is the main shortcome of bitproto serialization until v0.4.0, since this version, it supports message’s extensiblity by adding two bytes indicating the message size at head of the message’s encoded buffer. This breaks the traditional data layout design by encoding some minimal reflection size information in, so this is designed as an optional feature.
Shortcomes¶
Known shortcomes of bitproto:
bitproto doesn’t support varying sized types. For example, a
unit37always occupies 37 bits even you assign it a small value like1.Which means there will be lots of zero bytes if the meaningful data occupies little on this type. For instance, there will be
n-1bytes left zero if only one byte of a type withnbytes size is used.Generally, we actually don’t care much about this, since there are not so many bytes in communication with embedded devices. The protocol itself is meant to be designed tight and compact. Consider to wrap a compression mechanism like zlib on the encoded buffer if you really care.
bitproto can’t provide best encoding performance with extensibility.
There’s an optimization mode designed in bitproto to generate plain encoding/decoding statements directly at code-generation time, since all types in bitproto are fixed-sized, how-to-encode can be determined earlier at code-generation time. This mode gives a huge performance improvement, but I still haven’t found a way to make it work with bitproto’s extensibility mechanism together.