一种比特级别的数据交换格式¶
简介¶
bitproto 是一种快速的、轻量的、易用的用来序列化结构化数据的比特级别数据交换格式。
bitproto 的协议描述语法和著名的 protocol buffers 类似,只不过是比特级别的:
proto example
message Data {
uint3 the = 1
uint3 bit = 2
uint5 level = 3
uint4 data = 4
uint11 interchange = 6
uint6 format = 7
} // 32 bits => 4B
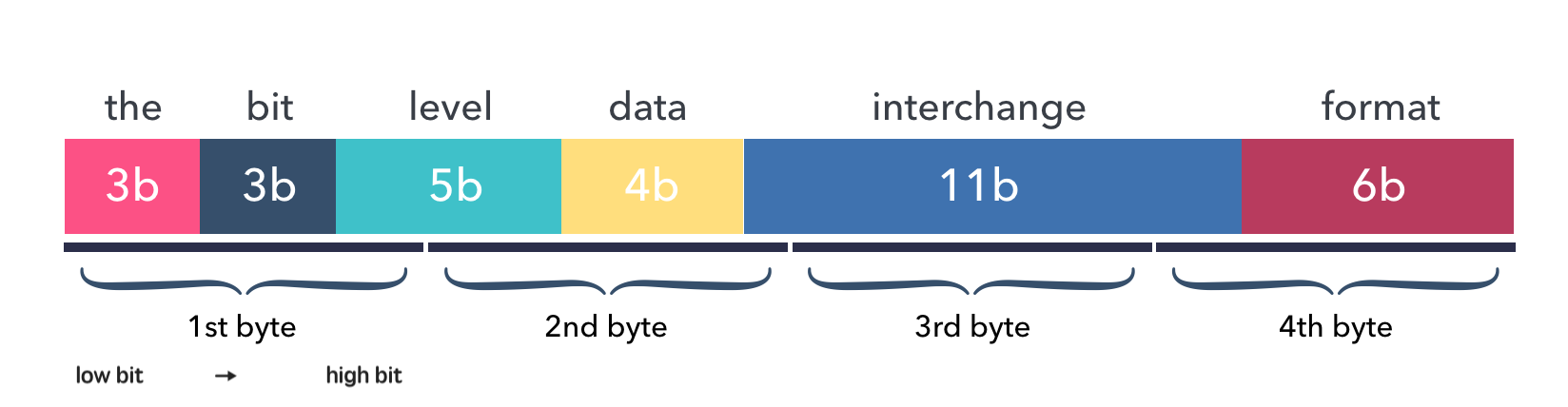
上面的 Data 是一个消息,它由 7 个字段构成,在编码后会占用 4 个字节。
这一张图片展示了编码后的字节流中数据字段的分布情况:
功能¶
支持比特级别的数据序列化, 为嵌入式开发而生
支持协议的 扩展性、向前兼容设计
容易上手,协议的语法类似著名的 protobuf.
支持的语言: C (无动态内存申请), Go 和 Python.
极快的编解码性能, 性能压测.
我们可以非常清晰的知道编码后数据的大小和排列,字段之间无任何比特缝隙.
代码示例¶
一个在 C 语言中编码 bitproto 消息的代码示例:
struct Data data = {.the = 7,
.bit = 7,
.level = 31,
.data = 15,
.interchange = 2047,
.format = 63};
unsigned char s[BYTES_LENGTH_DATA] = {0};
EncodeData(&data, s);
// length of s is 4, and the hex format is
// 0xFF 0xFF 0xFF 0xFF
下面的是一个解码的例子:
struct Data d = {0};
DecodeData(&d, s);
// values of d's fields is now:
// 7 7 31 15 2047 63
非常简单,不是吗?
对于 Go 和 Python 语言,bitproto 的编解码的代码也是类似的。你可以前往 快速开始的文档 获取进一步的引导内容。
为什么会有 bitproto ?¶
已经有 protobuf 了,为什么要做 bitproto 呢?
由来¶
bitproto 最初是我在和微型控制器上的嵌入式程序打交道的时候创作的。在嵌入式的环境中,经常会有许多开发上的约束:
紧凑的通信量
受限制的固件大小
最好不要有动态内存的使用
Protobuf 天生不是为了嵌入式领域的,它没有开箱即用的纯 C 语言的支持。
场景¶
对于以下的场景,是推荐使用 bitproto ,而非 protobuf 的:
当你的程序需要在微型控制器上运行,或者 你的程序需要和嵌入式程序通信。
想要有比特级别的数据字段
想要从协议设计上清楚地知道编码后的数据会占用多少字节
对于其他场景,则推荐考虑 protobuf ,而不是 bitproto .
和 Protobuf 相比¶
bitproto 和 protobuf 的不同点有:
bitproto 支持比特级别的数据序列化,类似 C 语言中的 bit fields.
bitproto 不使用任何动态内存。很少有 protobuf 的 C 语言实现 支持这点,除了 nanopb.
bitproto 不支持变长数据,所有类型都是定长的.
bitproto 不会把任何类型信息或者反射信息编码到字节流中。它只编码数据本身,编码后的数据排列就和内存中一样,定长且不带有任何字节缝隙,就像在C 语言中设置 结构体的对齐为 1 字节 一样。
对于 bitproto,直到 v0.4.0 之前,向前兼容都是其一个主要的缺点。自从这个版本之后,bitproto 通过在编码后的字节流头部新增两个字节的方式实现了 扩展性 的支持,这两个字节存储了相关消息的占用字节数的多少。这个设计打破了 bitproto 传统的编码结构的设计,因为新增了一些对于编码大小的反射信息,因此这个功能被设计为可选的。
缺点¶
已知的 bitproto 的缺点如下:
bitproto 不支持变长数据类型。 举例来说,一个
uint37类型的数据永远在编码后占用 37 个比特,即使你赋值它一个诸如1这样很小的值。这意味着,如果有意义的数据占用类型的占比较小的时候,编码后的数据中会有很多零字节。比如,当一个大小为
n个字节的类型只被使用了其中一个字节的时候,会有n-1个字节会是零字节。一般来说,我们并不特别关心这个问题,因为在嵌入式设备上的通信量一般不会有多少字节。这里的协议自身一般要设计地紧凑一些。如果你真的比较关心这个问题,可以考虑使用 zlib 类似的压缩机制,在消息编码后进行一次协议压缩。
bitproto 无法同时提供 最佳的性能 和 扩展性能力。
bitproto 中设计了一种 优化模式 ,这个模式下,编译器会直接生成直白的编解码的语句,以达到更好的编解码性能。因为 bitproto 中所有的类型都是定长的,因此我们可以在代码生成阶段就清楚地知道如何对其进行编解码。压测的结果表明,这个模式带来了巨大的性能提升,不过目前为止我还没有想到一个办法来支持 bitproto 的扩展性功能和这个性能优化模式一起工作。